Zabbix is a robust open-source solution for monitoring IT infrastructure, allowing tracking and analysis of network, server, application performance, and other components. As the amount of data grows, efficient management of time-series data becomes a key factor. Therefore, starting from version 5.0, Zabbix began supporting TimescaleDB, an extension of PostgreSQL optimized for time series. This article focuses on the benefits of using TimescaleDB in Zabbix, key tables, and the installation process.
NOTE: The current version of TimescaleDB DOES NOT yet work with the latest PostgreSQL (18)
Benefits of TimescaleDB in Zabbix
TimescaleDB brings several significant advantages to Zabbix, increasing performance and efficiency when working with large volumes of time-series data:
- Scalability and Performance: TimescaleDB is designed to efficiently manage large amounts of time-series data. Thanks to the hypertables architecture, it allows for fast data writes and reads, which is crucial for monitoring systems like Zabbix that generate huge amounts of metrics.
- Data Compression: TimescaleDB offers the ability to compress historical data, reducing storage requirements and potentially leading to up to 90% disk space savings. However, compression prevents the modification of already compressed data; for any modifications, data must first be decompressed, altered, and then recompressed.
- Easy Management: TimescaleDB is fully compatible with PostgreSQL, meaning administrators familiar with PostgreSQL can easily navigate TimescaleDB as well. Implementation is straightforward and adds minimal overhead costs to database management. Furthermore, some TimescaleDB settings can be adjusted directly in the Zabbix administration, specifically in Administration > Housekeeping.
Tables in Zabbix utilizing TimescaleDB
Zabbix uses TimescaleDB to store a large amount of time-series data, which is divided into several key tables. To make this process efficient and well managed, a special structure called a hypertable is used, designed to work with time-series data in TimescaleDB. To facilitate the conversion of existing tables to hypertables and optimize the management of this data, the file /usr/share/zabbix-sql-scripts/postgresql/timescaledb/schema.sql contains the necessary commands. This script automates the conversion of key Zabbix tables to hypertables, ensuring efficient handling of large volumes of data.
Note: Starting from Zabbix version 7.2, the schema.sql script for TimescaleDB is located in the following path:/usr/share/zabbix/sql-scripts/postgresql/timescaledb/schema.sql.
Each command in the script utilizes the create_hypertable function, which is crucial for converting regular PostgreSQL tables to hypertables. Hypertable works by automatically managing data in smaller sub-tables called chunks. This division allows for efficient querying and storage of data, essential for quick access to large amounts of time series. The process of converting tables to hypertables involves several important parameters:
- Table Name (e.g.,
'history_text'): Specifies which table will be converted to a hypertable. In the case of thehistory_texttable, it contains textual data such as messages and logs monitored in Zabbix. - Time Column (e.g.,
'clock'): This parameter defines the column containing timestamps, essential for dividing data into individual chunks. The'clock'column specifies the time when the data was recorded, allowing for proper data partitioning and sorting. chunk_time_interval(e.g.,86400): This parameter determines the time interval in seconds for individual chunks. A value of86400seconds corresponds to one day. This means that all data collected within one day will be stored in one chunk. This interval can be customized according to performance requirements and the amount of data to be processed.migrate_data(e.g.,true): When this parameter is set totrue, all existing data in the table is automatically migrated to the new chunk structure. This feature is crucial when converting existing tables to hypertables to prevent data loss.if_not_exists(e.g.,true): This parameter ensures that if the hypertable already exists, the command will not recreate it, preventing potential errors and data loss. If the hypertable does not yet exist, it will be newly created.
By using these TimescaleDB settings, efficient management and access to large volumes of time-series data are ensured, which is essential for systems like Zabbix that generate and analyze large amounts of metrics. The key tables that have been converted to hypertables for better performance and efficiency are listed below:
history: Stores numeric data with floating point.
PERFORM create_hypertable('history', 'clock', chunk_time_interval => 86400, migrate_data => true, if_not_exists => true);history_uint: Stores integer values.
PERFORM create_hypertable('history_uint', 'clock', chunk_time_interval => 86400, migrate_data => true, if_not_exists => true);history_log: Contains logging information.
PERFORM create_hypertable('history_log', 'clock', chunk_time_interval => 86400, migrate_data => true, if_not_exists => true);history_text: Stores textual data such as messages and logs.
PERFORM create_hypertable('history_text', 'clock', chunk_time_interval => 86400, migrate_data => true, if_not_exists => true);history_str: Stores short text strings.
PERFORM create_hypertable('history_str', 'clock', chunk_time_interval => 86400, migrate_data => true, if_not_exists => true);history_bin: Stores binary data. (Since version 7.0.2)
PERFORM create_hypertable('history_bin', 'clock', chunk_time_interval => 86400, migrate_data => true, if_not_exists => true);auditlog: Contains user activity logging information. (Since version 7.0)
PERFORM create_hypertable('auditlog', 'auditid', chunk_time_interval => 604800, time_partitioning_func => 'cuid_timestamp', migrate_data => true, if_not_exists => true);trends: Stores aggregated historical metric data.
PERFORM create_hypertable('trends', 'clock', chunk_time_interval => 2592000, migrate_data => true, if_not_exists => true);trends_uint: Stores aggregated historical data for integer metrics.
PERFORM create_hypertable('trends_uint', 'clock', chunk_time_interval => 2592000, migrate_data => true, if_not_exists => true);Installation of TimescaleDB in Zabbix
Preparation for installation
Before starting the installation of TimescaleDB, it is necessary to have PostgreSQL installed and also the zabbix-sql-scripts package from the official repository for the specific version of Zabbix being used. While Zabbix itself may not necessarily be installed, the mentioned zabbix-sql-scripts package is essential as it contains the necessary SQL scripts for configuring the database. For PostgreSQL, it is recommended to install from the official PostgreSQL repository rather than using the system repository to ensure compatibility and access to the latest features and security fixes.
It is important to note that all the following commands and settings are performed only on the PostgreSQL server. Installing TimescaleDB from the official TimescaleDB repository, which supports the community version license, allows access to advanced features such as data compression. With the community license, users have the option to utilize compression, which can significantly reduce storage requirements and improve query performance on historical data.
Adding the official TimescaleDB repository
To install TimescaleDB from the official repository, the repository needs to be added to the system. On RHEL-based distributions such as Rocky Linux, follow these steps:
tee /etc/yum.repos.d/timescale_timescaledb.repo <<EOL
[timescale_timescaledb]
name=timescale_timescaledb
baseurl=https://packagecloud.io/timescale/timescaledb/el/$(rpm -E %{rhel})/\$basearch
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/timescale/timescaledb/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
EOLInstall TimescaleDB.
Replace the version number (16) with the version of PostgreSQL you are using.
dnf install timescaledb-2-postgresql-16 timescaledb-2-loader-postgresql-16Run the timescaledb-tune utility and pass a higher value for the maximum number of connections (--max-conns), set to 125 for these testing purposes.
This utility is used to adjust the default PostgreSQL settings for performance and appropriately configure PostgreSQL parameters for working with TimescaleDB.
This utility will also help us select the current and valid PostgreSQL configuration file through the installation wizard and set up automatic loading of TimescaleDB libraries.
Please respond “yes” (y) to all questions. Note that the automatic tuner assumes that PostgreSQL is running on a standalone server, so parameters may need to be adjusted accordingly.
Replace the version number (16) with the version of PostgreSQL you are using.
timescaledb-tune --pg-config /usr/pgsql-16/bin --max-conns=125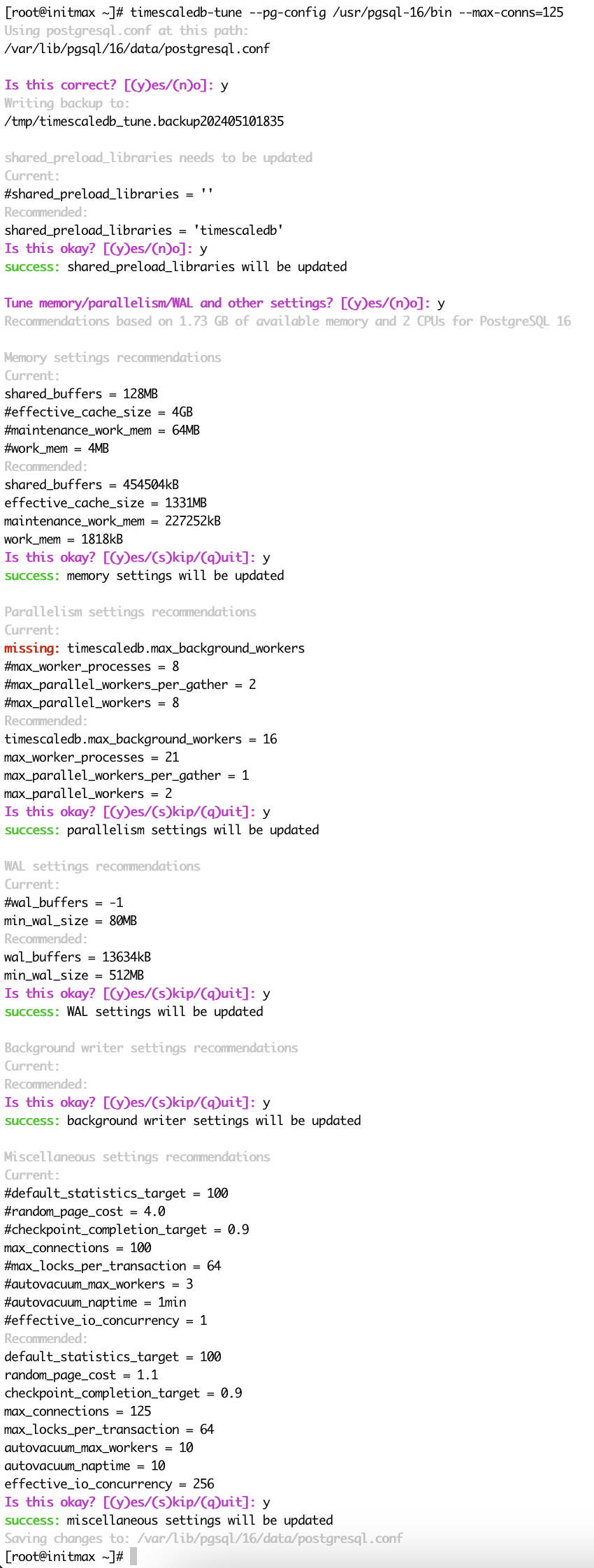
Then restart the system service for PostgreSQL:
Replace the version number (16) with the version of PostgreSQL you are using.
systemctl restart postgresql-16.serviceAll that’s left is to create and activate TimescaleDB itself:
Note that during development, the path has changed from the original /usr/share/zabbix-sql-scripts/postgresql/timescaledb.sql to the new /usr/share/zabbix-sql-scripts/postgresql/timescaledb/schema.sql.
Note: Starting from Zabbix version 7.2, the schema.sql script for TimescaleDB is located in the following path:/usr/share/zabbix/sql-scripts/postgresql/timescaledb/schema.sql.
Ignoring warnings: When running the schema.sql script on TimescaleDB version 2.9.0 and higher, warnings about non-compliance with best practices may appear. These warnings can be ignored as the configuration will be successfully completed despite them.
Long migration time: Migrating existing historical data, trends, and audit logs can take a long time. !!! During this time, the Zabbix server and frontend must be turned off !!! to ensure data consistency.
For Zabbix version 7.0 and earlier:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
cat /usr/share/zabbix-sql-scripts/postgresql/timescaledb/schema.sql | sudo -u zabbix psql zabbixStarting from Zabbix version 7.2:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
cat /usr/share/zabbix/sql-scripts/postgresql/timescaledb/schema.sql | sudo -u zabbix psql zabbix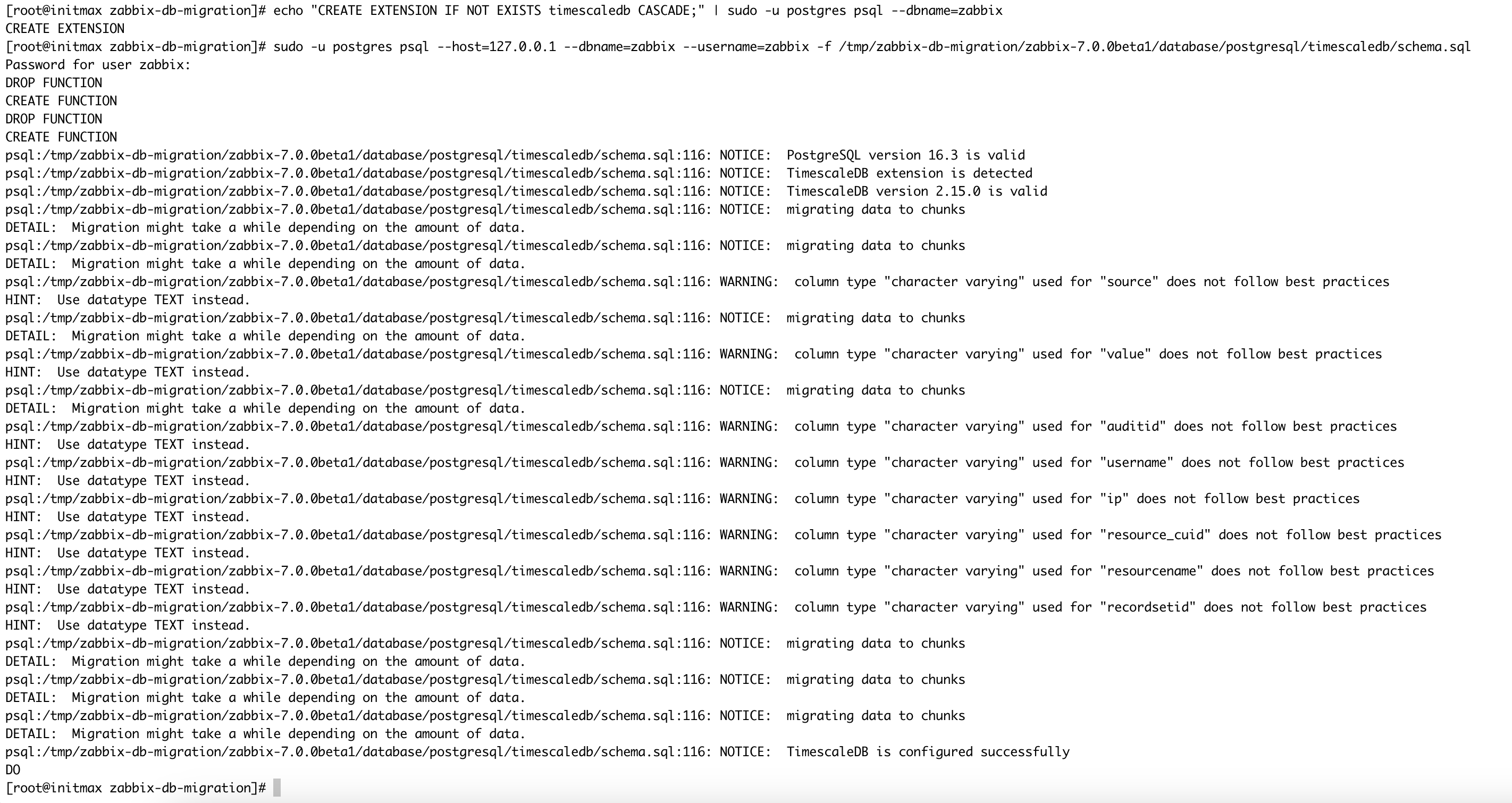
Additional information
Setting cleanup parameters (Administration > Housekeeping): The schema.sql script sets the following cleanup parameters:
- Override item history period: Allow overriding the item history retention period.
- Override item trend period: Allow overriding the trend retention period.
Both of these options must be enabled to use partitioned housekeeping for history and trends. It is also possible to enable overriding for history only or trends only. If the setting is applied, item-level history and trend settings will be ignored.
Other parameters in the schema.sql script: This script also sets two additional parameters:
- Enable compression: Allow compression.
- Compress records older than 7 days: Compress records older than 7 days.
To successfully remove compressed data using the housekeeper, both Override item history period and Override item trend period options must be enabled. If overriding is deactivated and tables have compressed chunks, the maintenance manager will not remove data from these tables, and warnings about incorrect configuration will appear in the Housekeeping and System Information sections.
If you see a message in the Zabbix Server log file stating that the TimescaleDB version is too new, that is not a significant problem. Zabbix may not be able to react quickly enough to the latest versions of TimescaleDB to set it as supported in its code, but compatibility with Zabbix is guaranteed and verified by us.

To avoid compatibility messages in the Zabbix log file, simply open the Zabbix server configuration file located at /etc/zabbix/zabbix_server.conf and adjust the following configuration parameter:
AllowUnsupportedDBVersions=1Save the file with this setting and restart the Zabbix server system service.
systemctl restart zabbix-serverAnd that’s it! You have successfully set up the extension for TimescaleDB and performed basic database performance tuning. The next steps should focus on backup and database monitoring.
Give us a Like, share us, or follow us 😍
So you don’t miss anything: